As everyone knows, it seems that Sony is taking a bit of a battering from hackers. Thanks to Sony, numerous account and password details are now circulating on the internet. Recently, Troy Hunt carried out a brief analysis of the password structure. Here is a summary of his post:
- There were around 40,000 passwords, of which 8000 would fail a simplistic dictionary attack;
- Only 1% of passwords contained non-alphanumeric passwords;
- 93% of passwords were between 6 and 10 characters.
In this post, we will investigate the remaining 32,000 passwords that passed the dictionary attack.
Distribution of characters
As Troy points out, the vast majority of passwords only contained a single type, i.e. all lower or all upper case. However, it turns out that things get even worst when we look at character frequency.
In the password database, there are a 78 unique characters. So if passwords were truly random, each character should occur with probability 1/78 = 0.013. However when we calculate the actual password occurrence, we see that it clearly isn’t random. The following figure shows the top 20 password characters, with the red line indicting 1/78.
 Unsurprisingly, the vowels “e”, “a” and “o” are very popular, with the most popular numbers being 1,2, and 0 (in that order). No capital letters make it into the top twenty. We can also construct the cumulative probability plot for character occurrence. In the following figure, the red dots show the pattern we would expect if the passwords were truly random (link to a larger version of the plot):
Unsurprisingly, the vowels “e”, “a” and “o” are very popular, with the most popular numbers being 1,2, and 0 (in that order). No capital letters make it into the top twenty. We can also construct the cumulative probability plot for character occurrence. In the following figure, the red dots show the pattern we would expect if the passwords were truly random (link to a larger version of the plot):

Clearly, things aren’t as random as we would like.
Character order
Let’s now consider the order that the characters appear. To simplify things, consider only the eight character passwords. The most popular number to include in a password is “1”. If placement were random, then in passwords containing the number “1” we would expect to see the character evenly distributed. Instead, we get:
##Distribution of "1" over eight character passwords 0.06 0.03 0.04 0.04 0.13 0.13 0.22 0.34
So in around of 84% of passwords that contain the number “1”, the number appears only in the second half of the password. Clearly, people like sticking a number “1” towards the end of their password.
We get a similar pattern with “2”:
0.05 0.05 0.04 0.05 0.13 0.11 0.30 0.27
and with “!”
#Small sample size here 0.00 0.00 0.00 0.00 0.00 0.11 0.16 0.74
We see similar patterns with other alpha-numeric characters.
Number of characters needed to guess a password
Suppose we constructed all possible passwords using the first N most popular characters. How many passwords would that cover in our sample? The following figure shows proportion of passwords covered in our list using the first N characters:
 To cover 50% of passwords in all list, we only need to use the first 27 characters. In fact, using only 20 characters covers around 25% of passwords, while using 31 characters covers 80% of passwords. Remember, these passwords passed the dictionary attack.
To cover 50% of passwords in all list, we only need to use the first 27 characters. In fact, using only 20 characters covers around 25% of passwords, while using 31 characters covers 80% of passwords. Remember, these passwords passed the dictionary attack.
Summary
Typically when we calculate the probability of guessing a password, we assume that each character is equally likely to be chosen, i.e. the probability of choosing “e” is the same as choosing “Z”. This is clearly false. Also, since many systems now force people to have different character types in their password, it is too easy for users just to tack on a number as their final digit. I don’t want to go into how to efficiently explore “password space”, but it’s clear that a brute force search isn’t the way to go.
Personally, I’ve abandoned trying to remember passwords a long time ago, and just use a password manager. For example, my wordpress password is over 12 characters and consists of a completely random mixture of alphanumeric and special characters. Of course, you just need to make sure your password manager is secure….
 uniformly over
uniformly over  .
. . return
. return  as the desired deviate.
as the desired deviate.![\mathcal C_h^{(1)} = \left\{ (y,z): 0 \le y \le [h(z/y)]^{1/2}\right\}.](https://s0.wp.com/latex.php?latex=%5Cmathcal+C_h%5E%7B%281%29%7D+%3D+%5Cleft%5C%7B+%28y%2Cz%29%3A+0+%5Cle+y+%5Cle+%5Bh%28z%2Fy%29%5D%5E%7B1%2F2%7D%5Cright%5C%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
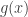 and
and 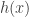 .
.