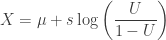Ratio-of-uniforms
This post is based on chapter 1.4.3 of Advanced Markov Chain Monte Carlo. Previous posts on this book can be found via the AMCMC tag.
The ratio-of-uniforms was initially developed by Kinderman and Monahan (1977) and can be used for generating random numbers from many standard distributions. Essentially we transform the random variable of interest, then use a rejection method.
The algorithm is as follows:
Repeat until a value is obtained from step 2.
- Generate
uniformly over
.
- If
. return
as the desired deviate.
The uniform region is
![\mathcal C_h^{(1)} = \left\{ (y,z): 0 \le y \le [h(z/y)]^{1/2}\right\}.](https://s0.wp.com/latex.php?latex=%5Cmathcal+C_h%5E%7B%281%29%7D+%3D+%5Cleft%5C%7B+%28y%2Cz%29%3A+0+%5Cle+y+%5Cle+%5Bh%28z%2Fy%29%5D%5E%7B1%2F2%7D%5Cright%5C%7D.&bg=ffffff&fg=333333&s=0&c=20201002)
In AMCMC they give some R code for generate random numbers from the Gamma distribution.
I was going to include some R code with this post, but I found this set of questions and solutions that cover most things. Another useful page is this online book.
Thoughts on the Chapter 1
The first chapter is fairly standard. It briefly describes some results that should be background knowledge. However, I did spot a few a typos in this chapter. In particular when describing the acceptance-rejection method, the authors alternate between 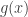
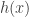
Another downside is that the R code for the ratio of uniforms is presented in an optimised version. For example, the authors use EXP1 = exp(1) as a global constant. I think for illustration purposes a simplified, more illustrative example would have been better.
This book review has been going with glacial speed. Therefore in future, rather than going through section by section, I will just give an overview of the chapter.
 , we generate a RN from an envelope distribution
, we generate a RN from an envelope distribution 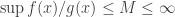 . The acceptance-rejection algorithm is as follows:
. The acceptance-rejection algorithm is as follows: from
from  from
from 
 , return
, return 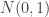 RNs using the logistic distribution as an envelope distribution. First, note that
RNs using the logistic distribution as an envelope distribution. First, note that
 , we get
, we get  . This method is fairly efficient and has an acceptance rate of
. This method is fairly efficient and has an acceptance rate of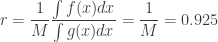
 and
and  are normalised densities.
are normalised densities.
 , where
, where  .
.  for
for  . This is shown in the following figure:
. This is shown in the following figure:
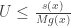 or
or 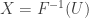
 is the inverse of the CDF. Well known examples of this method are the
is the inverse of the CDF. Well known examples of this method are the