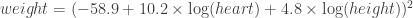These are my rough notes on the Kaleidoscope Ic session.
David Smith – The R Ecosystem (useR! 2011)
David Smith works for Revolution Analytics. Quick overview of the R project – useR, r-journal, and r-forge. Social media starting to play a part in R – Google+, twitter, stackoverflow, and the traditional R mailing list. The developer community is fairly large in github ~1100 repositories. Crantastic! gives a “rating” from the community. Also the local R user groups and video Rchive.
Companies are gradually recognising that R can be useful – Google, facebook, lloyd’s, Thomas Cook, bing, trulia, and techcrunch. A number of companies are based around R. A crude estimate is that there are 1.2M R users in industry and around 1M academia.
A lot of growth in jobs with R – see indeed.com for numbers. Slides are available online at some point.
James Harner – Rc2: R collaboration in the cloud
Rc2 is a web 2.0 front-end to R which is cloud based, scalable, collaborative, cross platform, touch optimized. Allows users to collaborate over the internet without concern for data becoming out of sync. A 4-tier architecture: client, application (ruby and Java), database: (postresql database for user information, Apache Cassandra for R files/code/data).
The client has a text editor, command line, voice chat, text output. Clients communicate asynchronously using websockets. Graphics in the browser can be closed, zoomed out and walked through as a slide show.
Security is taken seriously. A 3-value token used for autologin, which:
- disables an account if someone attempts to hijack a session
- limits session to a single browser
- another point that I missed 😦
Used a lot in teaching. Particularly useful for distance based learning. Walking through an example, communicating by voice, pass control to a student, take control. A full content management system is planned for the future.
J.J. Allaire – RStudio: Integrated Development Environment for R
RStudio just released in March. It’s a new open source project, focused on coding productivity. Support for Windows, Mac, Linux, or via the web. RStudio is a coding tool not an R GUI. Intelligent code completion facilities, for example “tab” completion, which gives suggestions and help files. Context sensitive help. Can also do intelligent rename. Also runs blocks or previous selections.
Nice use of the History file for browsing. Easy to search. Puts timestamps next to the commands. In the pipeline is code navigation. Type the function name, and it searches the function within a file.
R encourages good software practices: sweave, sharing/documenting code and version control. In the pipeline is to add version control, debugging tools and project management to RStudio.
RStudio is a company. Looking to build a company around offering education and help – RStudio is open source! In 10 years it will be almost impossible to justify NOT using open source software in science.
Personal note: I think I may use this for teaching.
Please note that the notes/talks section of this post is merely my notes on the presentation. I may have made mistakes: these notes are not guaranteed to be correct. Unless explicitly stated, they represent neither my opinions nor the opinions of my employers. Any errors you can assume to be mine and not the speaker’s. I’m happy to correct any errors you may spot – just let me know! The above paragraph was stolen from Allyson Lister who makes excellent notes when she attend conferences.